/bin/mallet import-dir --input sample-data/web/en --output tutorial.mallet --keep-sequence --remove-stopwordsTOPIC MODELING WITH MALLET, from the command line
A topic model provides a statistical breakdown of the frequency with which words tend to cluster or co-occur across a set of texts. It is not a simple word count, however. Instead, it is reaching across multiple texts to find patterns of co-occurrence*** by pooling these words together and then looking for tendencies across the pool. A word frequency analysis provides a simple, accurate count. A topic model, on the other hand, offers a kind of prediction about about how words relate to each other across the corpus, as a whole. In this tutorial you will learn how to make a topic model from your command line and save your output to designated folders. You will need admin access to get this set up on your own computer. If that is not possible, you should try this: https://mimno.infosci.cornell.edu/jsLDA/
This tutorial is a summary of: Shawn Graham, Scott Weingart, and Ian Milligan’s, “Getting Started with Topic Modeling and MALLET,” The Programming Historian 1 (2012), https://programminghistorian.org/en/lessons/topic-modeling-and-mallet.
**A note about co-occurrence here: in this case, it’s NOT the same as a concordance. In other words, word order has NOTHING TO DO WITH THIS NUMBER! So what is co-occurring? Topic Modeling uses the “bag of words” model to measure your texts. Imagine that your text can be chopped up into individual words. Now imagine that each and every one of these words (except those identified in your stop list) is put on a little tile and thrown into a bag–exactly like the beginning of a game of scrabble except instead of letters on the tiles, each tile has a word on it. And we are talking about tokens, not types. So what about repeated words? Yup. If a text uses the word “frabjous” 1,000 times, there will be 1,000 individual tiles with the word “frabjous” on it–at first! Like Scrabble Mallet starts pulling words out of the bag and once they are pulled out they are set aside–no longer in the bag. It pulls out pairs of words randomly, and starts to keep track of how often each word gets pulled with another. Topic modeling demonstrates statistical frequency of words that “co-occur” when they are pulled at random from the bag. At first, these pairings are kind of nonsensical, but after a while, patterns begin to emerge and are sorted into different “topics.” Again, however, these co-occurring pairs have NO TIE TO SYNTAX.
INSTRUCTIONS
1. GET YOUR CORPUS READY. Here are some tips:
- Unify your corpus around an author, theme, time period, etc. For example: Mark Twain, 19th century American literature, humor, etc.
- Gather as many documents as possible that relate to your corpus’ identity.
- Topic models are most useful with lots of files. The more the merrier.
- Happily, there are many already-ready corpora in existence. Google your topic and see what you find.
- Use text files only. This means each file in your corpus should end in .txt
- If you can only find .pdf files, you must convert .pdf files to .txt. Adobe’s “wizard” is good for this. See this tutorial if you need to.
- Keep your corpus (i.e., your .txt files) in a folder on your desktop.
2. DOWNLOAD MALLET
- you need mallet in your USERS folder.
- Instructions for download here: https://programminghistorian.org/en/lessons/topic-modeling-and-mallet
3. NOTE WHAT GOES WHERE
Mallet is in your users folder. The folder wont be called mallet though. It will be called mallet-2.0.8.
Mallet keeps the .txt files in a folder called “sample data.” Duplicate the following folder and move the copy somewhere convenient:
Users/mallet-2.0.8/sample data/web/eng
Or, you can take it step by step:
- open users folder
- open the mallet-2.0.8 folder
- look for this folder: sample data/web/eng
- duplicate this folder
- move the duplicate somewhere else in case you ever want to go back to the sample files. On my computer I duplicated it, renamed it “mallet original txt files”, and moved this new folder to the main Mallet folder.
- after you’ve made a copy, empty the sample/data/web/eng folder out.
3. ADD YOUR CORPUS
- now that it’s empty, add your texts to this folder.
- (your .txt files should be in that folder you made on your desktop; see the last part of Step #1)
- select all items in your corpus
- move them into sample/data/web/eng
- close this folder and re-open it to confirm that your text files are there.
4. OPEN COMMAND LINE / TERMINAL
- Open terminal.
- (It is in your applications folder: Applications/Utilities/Terminal)
- (If you haven’t already done so, make a shortcut to terminal at the bottom of your desktop by dragging it there.)
5. NAVIGATE TO MALLET (mallet-2.0.8) IN TERMINAL
- first navigate to your user folder; at bash prompt type: cd .. (note that this is cd SPACE ..)
- Are you there? If you’re not sure, check; at bash prompt type: pwd (This will print your working directory. I always forget that dang space, so that bolded instruction above is for both of us)
- At bash prompt, navigate to the mallet folder: cd mallet-2.0.8
6. MAKE A TOPIC MODEL WITHOUT SAVING ANY DATA
Nota bene:
- the following code uses both hyphens (-) and double hyphens (–). The double hyphen here is NOT a dash.
- keep it plain text; don’t copy and paste from this post as it will most likely not work. WordPress is highly formatted, as is Word and documents in .pdf.
- there is a txt version of this whole tutorial in our dropbox folder, however, and you are welcome to it!
- If you want to copy and paste, do so through a plain text editor (I use TextWrangler and/or BBedit)
- keep the following code on ONE LINE each. (if goes to another line on its own, that is fine; but don’t press return or format it in any way; hard-wraps frack it up. It wraps here for instructional purposes only (because it’s easier to read that way)
- at bash prompt type: ./bin/mallet and then press enter
- at bash prompt type: bin/mallet import-dir –help and then press enter
- at bash prompt type: bin/mallet import-dir –input sample-data/web/en –output tutorial.mallet –keep-sequence –remove-stopwords and then press enter
- at bash prompt type: bin/mallet train-topics –input tutorial.mallet and then press enter
7. MAKE A TOPIC MODEL AND SAVE YOUR OUTPUT TO SPECIFIED FOLDERS
Nota bene: Same as above (#6) except for the following:
- If you want to change your corpus, you need to update your code. Otherwise you will write over your already existing output files rather than create new ones.
1. at bash prompt: ./bin/mallet
2. at bash prompt: bin/mallet import-dir –help
3. at bash prompt: bin/mallet import-dir –input sample-data/web/en –output tutorial.mallet –keep-sequence –remove-stopwords
4. for this final following line: swap out the words in bold below for your own words. If you don’t, you will keep over-writing files each time you make a topic model: NOTE THAT EACH EXAMPLE BELOW (a-e) IS CUSTOMIZED FOR A SPECIFIC CORPUS
a. THIS IS FROM THE ORIGINAL TUTORIAL: note that “compostion” is mis-spelled in the online tutorial text below. At bash prompt type or copy plain text:
bin/mallet train-topics –input tutorial.mallet –num-topics 20 –output-state topic-state.gz –output-topic-keys tutorial_keys.txt –output-doc-topics tutorial_compostion.txt
b. THIS IS FOR A TOPIC MODEL OF A GAME OF THRONES CORPUS: “thrones_composition” is specific to the “Game of Thrones” corpus here, with composition now spelled correctly. At bash prompt type or copy plain text:
bin/mallet train-topics –input tutorial.mallet –num-topics 20 –output-state thrones-state.gz –output-topic-keys thrones_keys.txt –output-doc-topics thrones_composition.txt
c. THIS IS FOR A SCIENCE FICTION STUDIES TOPIC MODEL. At bash prompt type or copy plain text:
bin/mallet train-topics –input tutorial.mallet –num-topics 20 –output-state sfs-state.gz –output-topic-keys sfs_keys.txt –output-doc-topics sfs_composition.txt
d. THIS IS FOR A TOPIC MODEL OF WILLIAM GIBSON’S FICTION. At bash prompt type or copy plain text:
bin/mallet train-topics –input tutorial.mallet –num-topics 20 –output-state gibson-state.gz –output-topic-keys gibson_keys.txt –output-doc-topics gibson_composition.txt
e. THIS IS FOR A TOPIC MODEL OF D.H. DEFINITIONS. At bash prompt type or copy plain text:
bin/mallet train-topics –input tutorial.mallet –num-topics 20 –output-state dh_definitions-state.gz –output-topic-keys dh_definitions.txt –output-doc-topics dh_definitions_composition.txt
8. FINDING YOUR RESULTS / OUTPUT
- Find your three output files: if you used the tutorial template, these will be called:
- 1) topic-state.gz (this will be a zip file)
- 2) tutorial_keys.txt
- 3) tutorial_compostion.txt
- These will be in the mallet-2.0.8 folder.
9. TIDY UP YOUR CORPUS AND MALLET FOLDERS
- make two new folders in your corpus folder on your desktop:
- 1. your_corpus_title_here
- 2. your_corpus_title_output
- This should look something like this:
- Go back to the mallet-2.0.8/sample/data/web/eng folder
- Select all your .txt files
- drag them over to the corpus/text_files_mytopicnamehere folder.
- Your mallet-2.0.8/sample/data/web/eng folder should now be empty
- Go back to the mallet-2.0.8 folder and locate your 3 output files
- Move/drag your 3 output files to mallet_output_mytopicnamehere in your corpus folder, which is on the desktop.
10. INTERPRETING YOUR RESULTS
Warning: This is the most difficult part. It can be super useful in terms of giving you an insight to a bunch of different texts. It can also be absolutely maddening, incoherent, daunting, and offer you up nothing but the knowledge and satisfaction that you gave it a shot. So don’t despair if you’re left more confused than illuminated. Jut pat yourself on the shoulder for trying. And keep trying.
For the following example, the corpus was made up of the books in the Song of Ice and Fire series by George R. R. Martin (aka Game of Thrones). Here is what each of those output files offers us.
1) thrones_keys.txt
- If you open up this zip file you’ll see something that looks like the image below.
- This will probably be your most legible output.
- It lists the top 20 topics that Mallet identified.
- It’s important to note that they are somewhat unhelpfully numbered 0-19, and not 1-20.
- Suck it up.
- Once you read these over, however, you might find that these topics are actually kind of useful, especially if you know the texts.

Another interesting thing: If you were to run this topic model again, you would get slightly different results.
Again, this is because it’s predicting rather than counting. Below is a screenshot of a slightly different result from the same corpus:

2) thrones_composition.txt
- If you open up this zip file you’ll see something that looks like the image below. This is pretty illegible.

- So take that same file and open it in Excel or Google sheets. It will look something like this:

- This is still illegible, but only because it is so small. That’s ok.
- Before we read it closely, just notice that each row includes the whole file name of each item in the corpus (in this case, each file is a whole book).
- Notice also that each item is followed by twenty cells filled with mysterious numbers.
- All we really need is a short title of each book (and, yes, those twenty mysterious cells associated with it). So let’s edit this so it’s easier for us to read.
- Below I’ve changed the whole file name to a short title and zoomed in so you can read it. This screen shot cuts off at G, but, rest assured, the file goes all the way through V.
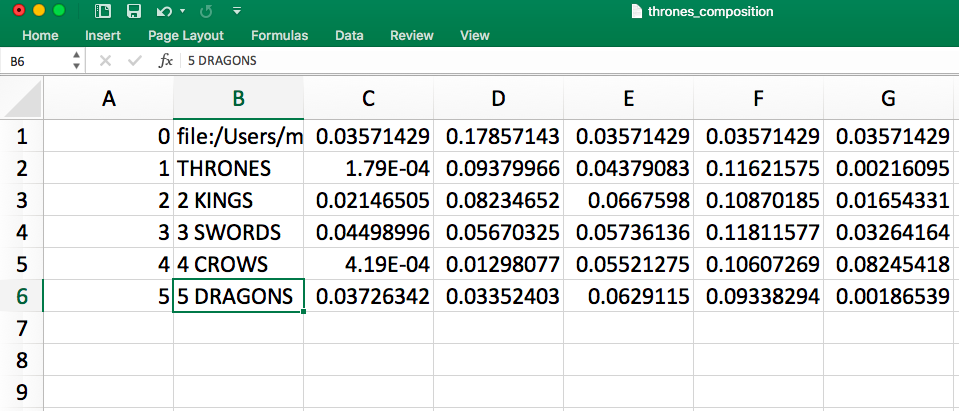
- So far so good for columns A-B. But what about columns C-V?
- Columns C-V correspond to the 20 topic models that Mallet identified in the thrones_keys.txt document.
- Column C = Topic 0. Column D = topic 1. Column E = topic 2. & so on until you get to topic #19, which = Column V (and which is really #20).
- I grant you that this is still illegible.
- But now you have a key! Or, rather, now you know what thrones_keys.txt will open for you.
- So of course you will want to compare these two documents to see which topic is what. So let’s do that.
- If we look at our first image of the thrones_keys.txt document, we can see that the first two topics (remember that these first two topics are unhelpfully labeled 0 and 1 instead of 1 and 20) are made up of the following words:
- TOPIC 0 / column C
0 0.25 dany davos hodor fire bolton meera jorah aye watch wedding wife mance melisandre wildling yellow belwas stood sail dogs river - TOPIC 1/ column D
1 0.25 tyrion jon brother bran maester blood king don’t horse great north wolf hard mormont bed horses lady back lannisters you’lL
- TOPIC 0 / column C
- So now we know that:
topic 0 corresponds to Column C.
topic 1 corresponds to Column D.
& so on until you get to Column V. - But what does it mean!!!????
- Ok, let’s go back to that spreadsheet and see.
- Our first book is THRONES (Game of Thrones).
- The number in column C (topic 0/19) for that row is this:
0.000178574294932502 - The number in column D (topic 1/19) for that row is this:
0.0937996597056132 - So, everything is clear now, right? HAHAHAHAHAHA.
Of course it’s not. - But now that you know what all the parts are, you just need to know what the relationship among them is. Basically, each of these numbers, once you convert it to a percentage, tells you how close this particular text corresponds to this particular topic.
- To make it specific: Each of these numbers, once you convert it to a percentage, tells you how close this particular text (in this case the novel, Game of Thrones) corresponds to this particular topic (in this case, topic 0/19: dany davos hodor fire bolton meera jorah aye watch wedding wife mance melisandre wildling yellow belwas stood sail dogs river)
- So let’s take that first number in Column C: 0.000178574294932502
converted to a percentage, that seems very low. Meh. Not very impressive. Is it any higher in any of the other books? Sort of, maybe, but still. Meh. - But let’s take a look at that number in column D (topic 1/19) for that row is this: 0.0937996597056132
converted to a percentage, this is actually legible as a percentage of something. Hrm. Interesting. What was topic 1/19 again?
topic 1/19: tyrion jon brother bran maester blood king don’t horse great north wolf hard mormont bed horses lady back lannisters you’ll - Very interesting! Since I know all of these characters and terms, I am intrigued that this particular book tracks them so closely. Do the other books do the same? My hunch is that because these are all central characters throughout the series–especially tyrion, jon, and bran–they might.
- Let’s look at column D for each text and compare. They are all legible as percentages, yes, but this particular book has the strongest/largest percentage compared to the others. This might be a useful topic. Why?
- Well, as the Princess Irulan once wrote in a similarly epic series: “A beginning is the time for taking the most delicate care that the balances are correct.”

- It’s important to set everything up in the beginning, perhaps by emphasizing characters and their relationships. This is not to say they fade off in subsequent works, but that more attention is paid at the beginning to establishing them. Or not. The only way you’re going to confirm this is through close reading. But this provides you with a solid lead.
- But we can all agree that this was a lot of work for not a very useful insight, but you might get lucky! You never know…
3) thrones-state.gz (this will be a zip)
If you open up the file in this zipped folder you’ll see something that looks like the image below. This is a break down of the occurrence of every single instance of every word in the entire corpus. Every. single. instance. In the ENTIRE CORPUS. Why? Dear God, Why would anyone need such a thing? I quote from a different Mallet tutorial, which has this to say: “this option outputs a compressed text file containing the words in the corpus with their topic assignments. Descriptive, yes, but not so helpful. So let’s look at this sucker.
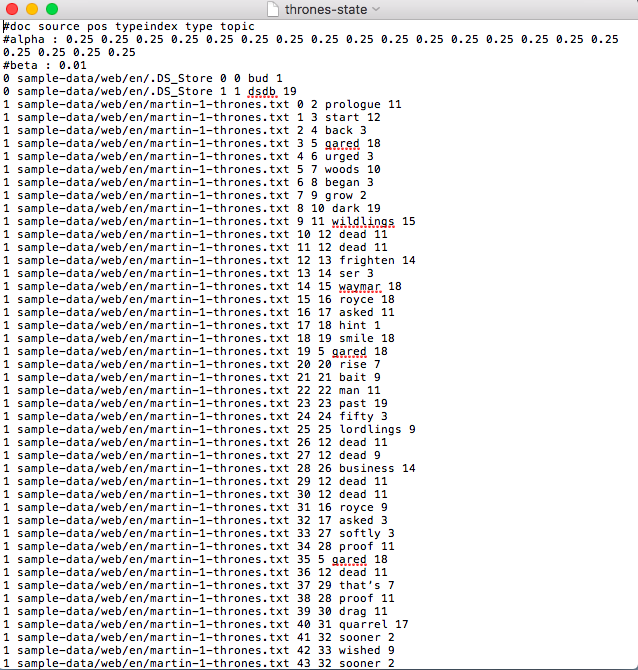
- The first line provides us with a breakdown of the content:
#doc source pos typeindex type topic - This identifies the document source, the position of the word in the index that mallet made of all these words (typeindex); the word index; the word itself; and the topic it corresponds to. Let’s look at the word “woods”:
1 sample-data/web/en/martin-1-thrones.txt 5 7 woods 10 - Garble-blargle! But, once again, we have the key and now we know the relations among these components.
- So for the above entry, for the word “woods,” we know it’s coming from text #1, Game of Thrones; its typeindex is 5; its type is 7; and it corresponds to topic 10.
- That last part is what you want to look at: Topic 10, which is:
beneath blood men sons woman tongue golden called hands return show grey child captain thousand cup peace girls coin pray - Well, this is interesting! Why?
- Because it suggests a relationship between the word “woods” and all of these creepy terms in topic 10. Would you have suspected such a relationship? Maybe. Probably. But you probably would not have thought to suspect anything about it without this prompt.




